SQL server内存问题排查方案
目录
- 前言
- 整体思路
- 查询数据库请求连接
- 查询数据库请求量
- 查询数据库阻塞语句以及执行语句
- 查询数据库语句执行时间
- 问题分析与定位
- 查询序列号表 tb_SN
- 查询序列号流水表 tb_SNs
- 使用压缩存储快速查看数据量
- 解析问题
前言
由于昨晚线上服务器数据库突然访问数据缓慢,任务管理里面SQL server进程爆满等等,重大事故的排查拟写解决方案。
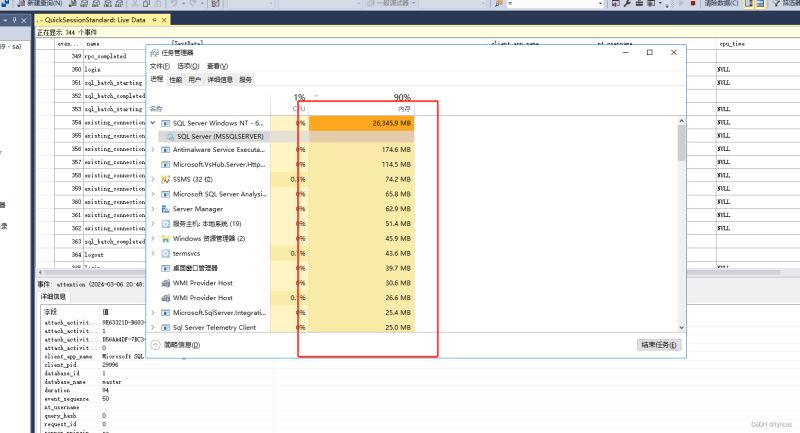
整体思路
- 查询数据库请求连接:排查连接池是否占满
- 查询数据库请求量:排查数据是否存在反复查询
- 查询数据库阻塞语句以及执行语句:排查数据库是否存在历史SQL语句阻塞以及当前执行的SQL语句是否存在问题
- 查询数据库语句执行时间:排查数据库是否因为数据量过大导致的
- 定位到问题指定位置
查询数据库请求连接
SELECT DB_NAME(dbid) AS DatabaseName, COUNT(*) AS ConnectionCount FROM sys.sysprocesses WHERE dbid > 0 GROUP BY dbid;
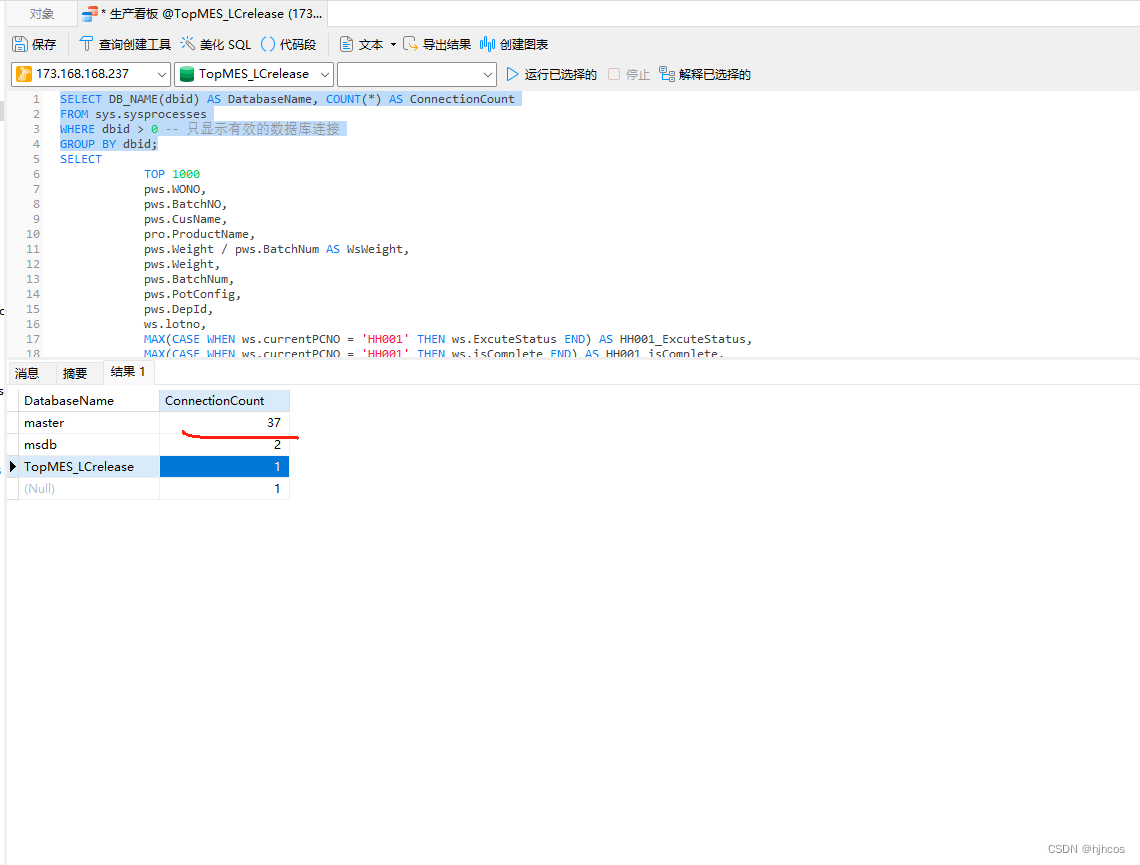
查看连接池比较正常,除了master主数据库存在大量连接,其他业务数据库正常,猜测应该是排查人员的连接池,不太确定具体原因,但是排除连接池超量的问题。
查询数据库请求量
SELECT client_net_address AS '客户端IP', COUNT(*) AS '请求次数' FROM sys.dm_exec_connections GROUP BY client_net_address ORDER BY COUNT(*) DESC;
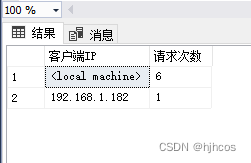
通过SQL语句排查是否存在大量重复数据请求量,显然并不是请求次数的问题,也就是说没有频繁的请求量,因此排除数据请求频繁的问题。
查询数据库阻塞语句以及执行语句
SELECT TOP 100 dest.[text] AS 'sql语句',session_id,status,start_time FROM sys.[dm_exec_requests] AS der CROSS APPLY sys.[dm_exec_sql_text](der.[sql_handle]) AS dest ORDER BY [cpu_time] DESC

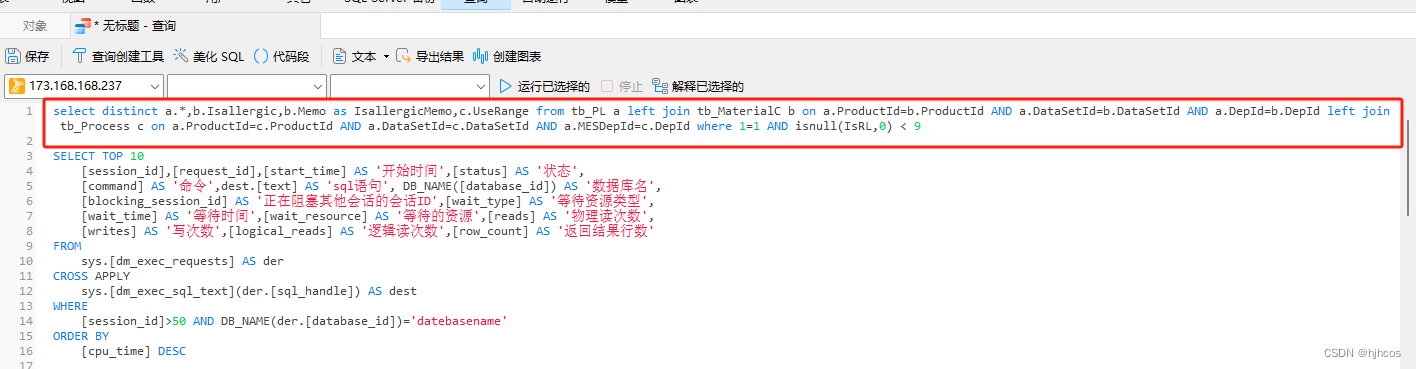
查询到数据库正在执行的SQL语句并不存在阻塞的SQL语句,发现当前在执行的SQL语句比较正常,单独执行这些SQL语句并不存在大量数据访问,最多六千条数据量,这个量很小,因此无法确定,但是可以确定数据库不存在问题,SQL语句也比较正常。
查询数据库语句执行时间
SELECT --TOP 20
total_worker_time / 1000 AS [自编译以来执行所用的CPU时间总量(ms)],
total_elapsed_time/1000 as [完成执行此计划所用的总时间],
total_elapsed_time / execution_count/1000 as [平均完成执行此计划所用时间],
execution_count as [上次编译以来所执行的次数],
creation_time as [编译计划的时间],
deqs.total_worker_time / deqs.execution_count / 1000 AS [平均使用CPU时间(ms)],
last_execution_time AS [上次开始执行计划的时间],
total_physical_reads [编译后在执行期间所执行的物理读取总次数],
total_logical_reads/execution_count [平均逻辑读次数],
min_worker_time /1000 AS [单次执行期间所用的最小CPU时间(ms)],
max_worker_time / 1000 AS [单次执行期间所用的最大 CPU 时间(ms)],
SUBSTRING(dest.text, deqs.statement_start_offset / 2 + 1,
(CASE
WHEN deqs.statement_end_offset = -1 THEN
DATALENGTH(dest.text)
ELSE deqs.statement_end_offset
END - deqs.statement_start_offset
) / 2 + 1) AS [执行SQL],
dest.text as [完整SQL],
db_name(dest.dbid) as [数据库名称],
object_name(dest.objectid, dest.dbid) as [对象名称]
,deqs.plan_handle [查询所属的已编译计划]
FROM sys.dm_exec_query_stats deqs WITH(NOLOCK)
CROSS APPLY sys.dm_exec_sql_text(deqs.sql_handle) AS dest
WHERE (max_worker_time / 1000)>100
--完成执行此计划所用的总时间降序
ORDER BY total_elapsed_time/1000 DESC
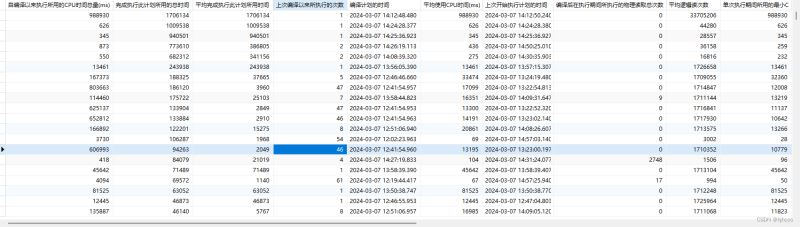
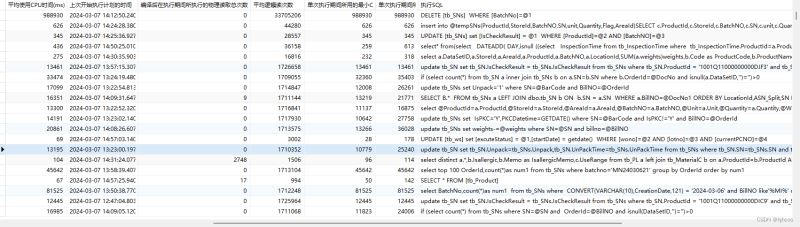
从SQL语句执行时间分析出(后补的图忽略第一个删除的操作),整体分析下来是 tb_SN 和 tb_SNs 两张表耗时严重,接下来只需使用查询语句查询两张表数量即可。
问题分析与定位
查询序列号表 tb_SN
SELECT COUNT(*) FROM tb_SN 243779 条
排查不是序列号表的问题,那么就只有序列号流水表的问题啦
查询序列号流水表 tb_SNs
SELECT COUNT(*) FROM tb_SNs
使用该命令果然执行时间缓慢,因此可以判断是数据量太大导致的。
使用压缩存储快速查看数据量
点击 tb_SNs 流水表 【右键】【存储】【管理压缩】【下一步】
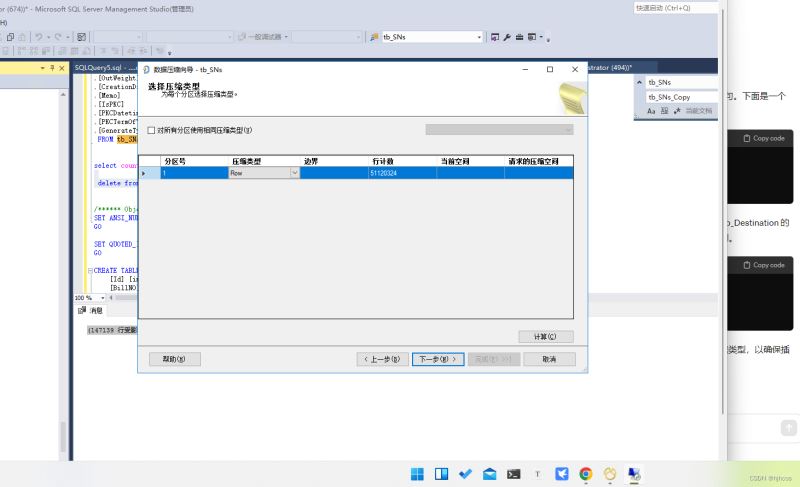
流水表五千万条数据,因此可以确定序列号流水表存在数据量过多导致的,整个和序列号流水相关的程序出现访问缓慢的问题。
竟然知道问题了,和相关领导咨询是否可以删除数据,并确定删除的时限范围,确定删除 2023 年以前的所有数据,释放数据量。
首先我们备份整个数据库防止误操作,然后复制并创建与 tb_SNs 的数据结构相同的表,接下来将 2023 年以前的所有数据拷贝到该表上,最后在删除 tb_SNs 的 2023 年以前的所有数据。
如此操作下,我们发现删除的数据量只有十万条,显然这是不对的,总共三年不到,不可能只有怎么点数据,因此判断是不是某个时间点插入大量数据,然后我们根据去年年份查询去年的数据量:
SELECT TOP 10 COUNT(*) FROM tb_SNs WHERE CreationDate < '2024-01-01' 571638
五十万条显然是今年数据量突然增加的,因此开始查询月时间节点产生的数据,发现三月以前都正常,数据出现在三月份,接下来开始查询每日的数据量,三月五号正常,三月六号出现五千万数据,因此问题出现在昨天的时候。
解析问题
接下来问题就好解决啦,首先根据主要数据查询事故发生节点,再通过事故发生节点咨询是否出现错误操作。
- 查询负责人该节点人员工作安排
- 根据业务确定程序是否存在逻辑判断插入问题
- 判断数据是否可以删除