redis大key和大value的危害及解决
目录
- 一、前序
- 二、什么是Redis大key问题
- 三、大key带来的影响
- 四、大key产生的原因
- 五、怎样排查大key
- SCAN命令
- bigkeys参数
- Redis RDB Tools工具
- 六、怎么解决大key
- 七、Redis 大key如何处理?
- 业务场景:
- 大key的风险:
- redis使用会出现大key的场景:
- 解决问题:
- 八、 大value数据是什么,会有怎样的问题?
- 九、怎么处理Redis大value?
- 十、总结
一、前序
还记得上次和同事一起去面试候选人时,同事提了一个问题:Redis的大key有什么危害?当时候选人主要作答的角度是一个key的value较大时的情况,比如:
- 内存不均:单value较大时,可能会导致节点之间的内存使用不均匀,间接地影响key的部分和负载不均匀;
- 阻塞请求:redis为单线程,单value较大读写需要较长的处理时间,会阻塞后续的请求处理;
- 阻塞网络:单value较大时会占用服务器网卡较多带宽,可能会影响该服务器上的其他Redis实例或者应用。
虽说答的是挺好的,但是我又随之产生了另一个疑惑,如果redis的key较长时,会产生什么样的影响呢?查了很多文章,说的都不是特别清楚。所以我决心探究一下这个问题。
我们需要知道Redis是如何存储key和value的:
根结构为RedisServer,其中包含RedisDB(数据库)。而RedisDB实际上是使用Dict(字典)结构对Redis中的kv进行存储的。这里的key即字符串,value可以是string/hash/list/set/zset这五种对象之一。
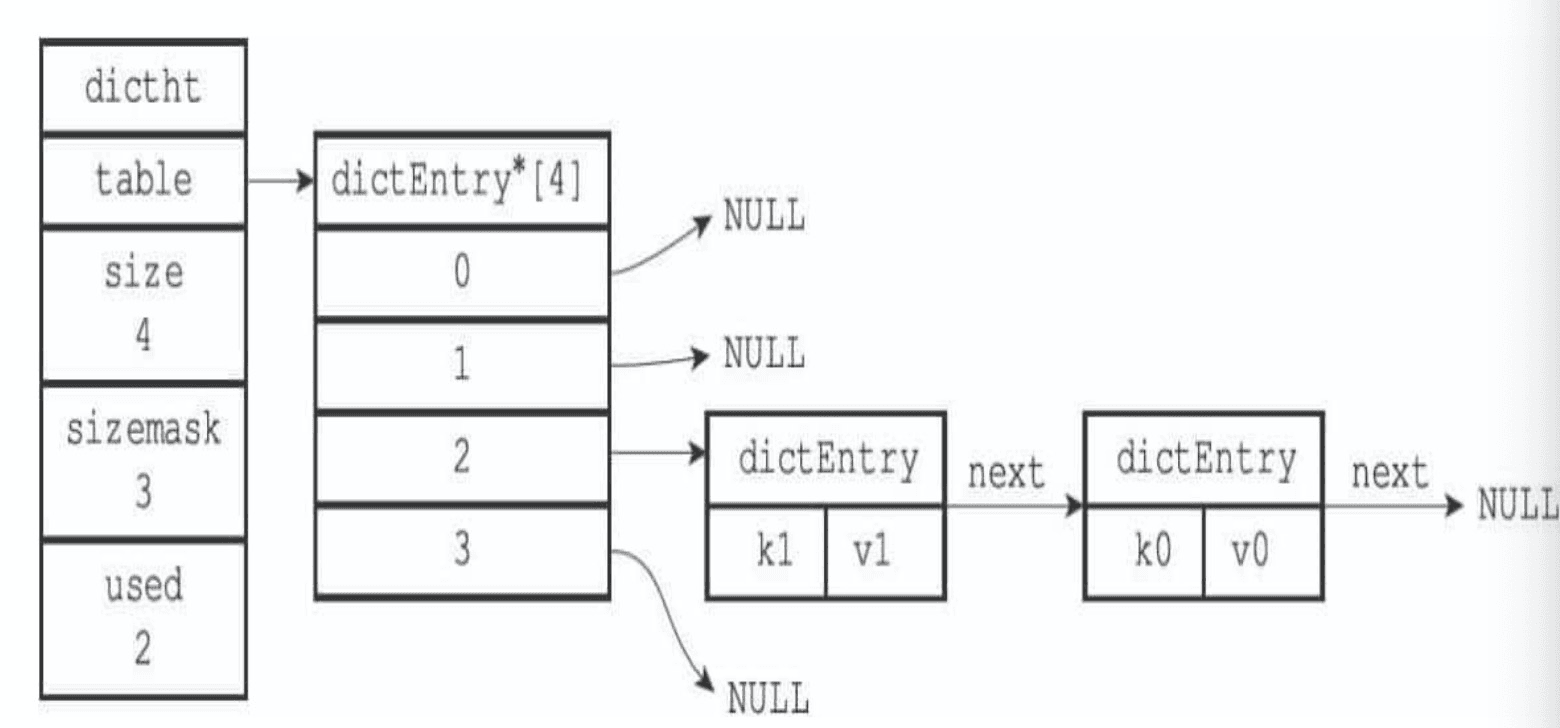
Dict字典结构中,存储数据的主题为DictHt,即哈希表。而哈希表本质上是一个DictEntry(哈希表节点)的数组,并且使用链表法解决哈希冲突问题(关于哈希冲突的解决方法可以参考大佬的文章 解决哈希冲突的常用方法分析)。
所以在这里实际存储时,key和value都是存储在DictEntry中的。所以基本上来说,大key和大value带来的内存不均和网络IO压力都是一致的,只是key相较于value还多一个做hashcode和比较的过程(链表中进行遍历比较key),会有更多的内存相关开销。
二、什么是Redis大key问题
Redis大key问题指的是某个key对应的value值所占的内存空间比较大,导致Redis的性能下降、内存不足、数据不均衡以及主从同步延迟等问题。
到底多大的数据量才算是大key?
没有固定的判别标准,通常认为字符串类型的key对应的value值占用空间大于1M,或者集合类型的k元素数量超过1万个,就算是大key。
Redis大key问题的定义及评判准则并非一成不变,而应根据Redis的实际运用以及业务需求来综合评估。例如,在高并发且低延迟的场景中,仅10kb可能就已构成大key;然而在低并发、高容量的环境下,大key的界限可能在100kb。因此,在设计与运用Redis时,要依据业务需求与性能指标来确立合理的大key阈值。
三、大key带来的影响
- 内存占用过高。大Key占用过多的内存空间,可能导致可用内存不足,从而触发内存淘汰策略。在极端情况下,可能导致内存耗尽,Redis实例崩溃,影响系统的稳定性。
- 性能下降。大Key会占用大量内存空间,导致内存碎片增加,进而影响Redis的性能。对于大Key的操作,如读取、写入、删除等,都会消耗更多的CPU时间和内存资源,进一步降低系统性能。
- 阻塞其他操作。某些对大Key的操作可能会导致Redis实例阻塞。例如,使用DEL命令删除一个大Key时,可能会导致Redis实例在一段时间内无法响应其他客户端请求,从而影响系统的响应时间和吞吐量。
- 网络拥塞。每次获取大key产生的网络流量较大,可能造成机器或局域网的带宽被打满,同时波及其他服务。例如:一个大key占用空间是1MB,每秒访问1000次,就有1000MB的流量。
- 主从同步延迟。当Redis实例配置了主从同步时,大Key可能导致主从同步延迟。由于大Key占用较多内存,同步过程中需要传输大量数据,这会导致主从之间的网络传输延迟增加,进而影响数据一致性。
- 数据倾斜。在Redis集群模式中,某个数据分片的内存使用率远超其他数据分片,无法使数据分片的内存资源达到均衡。另外也可能造成Redis内存达到maxmemory参数定义的上限导致重要的key被逐出,甚至引发内存溢出。
四、大key产生的原因
- 业务设计不合理。这是最常见的原因,不应该把大量数据存储在一个key中,而应该分散到多个key。例如:把全国数据按照省行政区拆分成34个key,或者按照城市拆分成300个key,可以进一步降低产生大key的概率。
- 没有预见value的动态增长问题。如果一直添加value数据,没有删除机制、过期机制或者限制数量,迟早出现大key。例如:微博明星的粉丝列表、热门评论等。
- 过期时间设置不当。如果没有给某个key设置过期时间,或者过期时间设置较长。随着时间推移,value数量快速累积,最终形成大key。
- 程序bug。某些异常情况导致某些key的生命周期超出预期,或者value数量异常增长 ,也会产生大key。
五、怎样排查大key
SCAN命令
通过使用Redis的SCAN命令,我们可以逐步遍历数据库中的所有Key。结合其他命令(如STRLEN、LLEN、SCARD、HLEN等),我们可以识别出大Key。SCAN命令的优势在于它可以在不阻塞Redis实例的情况下进行遍历。
bigkeys参数
使用redis-cli命令客户端,连接Redis服务的时候,加上 —bigkeys 参数,可以扫描每种数据类型数量最大的key。
redis-cli -h 127.0.0.1 -p 6379 —bigkeys
Redis RDB Tools工具
使用开源工具Redis RDB Tools,分析RDB文件,扫描出Redis大key。
例如:输出占用内存大于1kb,排名前3的keys。
rdb —commond memory —bytes 1024 —largest 3 dump.rbd
六、怎么解决大key
拆分成多个小key。这是最容易想到的办法,降低单key的大小,读取可以用mget批量读取。
数据压缩。使用String类型的时候,使用压缩算法减少value大小。或者是使用Hash类型存储,因为Hash类型底层使用了压缩列表数据结构。
设置合理的过期时间。为每个key设置过期时间,并设置合理的过期时间,以便在数据失效后自动清理,避免长时间累积的大Key问题。
启用内存淘汰策略。启用Redis的内存淘汰策略,例如LRU(Least Recently Used,最近最少使用),以便在内存不足时自动淘汰最近最少使用的数据,防止大Key长时间占用内存。
数据分片。例如使用Redis Cluster将数据分散到多个Redis实例,以减轻单个实例的负担,降低大Key问题的风险。
删除大key。使用UNLINK命令删除大key,UNLINK命令是DEL命令的异步版本,它可以在后台删除Key,避免阻塞Redis实例。
七、Redis 大key如何处理?
Redis使用过程中经常会有各种大key的情况, 比如:
单个简单的key存储的value很大
hash, set,zset,list 中存储过多的元素(以万为单位)
由于redis是单线程运行的,如果一次操作的value很大会对整个redis的响应时间造成负面影响,所以,业务上能拆则拆,下面举几个典型的分拆方案。
业务场景:
即通过hash的方式来存储每一天用户订单次数。那么key = order_20200102, field = order_id, value = 10。那么如果一天有百万千万甚至上亿订单的时候,key后面的值是很多,存储空间也很大,造成所谓的大key。
大key的风险:
读写大key会导致超时严重,甚至阻塞服务。
如果删除大key,DEL命令可能阻塞Redis进程数十秒,使得其他请求阻塞,对应用程序和Redis集群可用性造成严重的影响。
redis使用会出现大key的场景:
- 单个简单key的存储的value过大;
- hash、set、zset、list中存储过多的元素。
解决问题:
- 单个简单key的存储的value过大的解决方案:
将大key拆分成对个key-value,使用multiGet方法获得值,这样的拆分主要是为了减少单台操作的压力,而是将压力平摊到集群各个实例中,降低单台机器的IO操作。
- hash、set、zset、list中存储过多的元素的解决方案:
1).类似于第一种场景,使用第一种方案拆分;
2).以hash为例,将原先的hget、hset方法改成(加入固定一个hash桶的数量为10000),先计算field的hash值模取10000,确定该field在哪一个key上。
将大key进行分割,为了均匀分割,可以对field进行hash并通过质数N取余,将余数加到key上面,我们取质数N为997。
那么新的key则可以设置为:
newKey = order_20200102_String.valueOf( Math.abs(order_id.hashcode() % 997) ) field = order_id value = 10 hset (newKey, field, value) ; hget(newKey, field)
八、 大value数据是什么,会有怎样的问题?
当String类型的数据>10K,list、hash、set、sort set中元素个数超过1000时就可以被称为大value,当超过100K,或集合元素个数超过10000时可以被称为是超大value。大value最直接的影响就是有可能造成机器内存不足,就是数据倾斜;同时因为redis数据处理是单线程的,当value过大时,处理起来响应时间也会变慢。 常见的例子有:参与人数很多的盖楼活动或者很活跃的群聊消息列表等
九、怎么处理Redis大value?
大value的处理方式还是结合业务,对其进行拆分,将其数据分布在各个redis节点中,将操作压力平摊开,防止对单个实例IO或内存影响过大。
简单说一下 热点数据和大value的拆分,如果它是一个list、 set集合类型,比如原来的 为key value,value为list为拆为 list1 、list2、list3,那么新的key为 key+hash(list1)%10000 得到新的key,再对对应数据value进行set或get操作
如果是一个对象的json字符串,可以考虑将该对象的不同属性映射到不同hash槽从而分布在不同redis节点中;或者将不同属性拆分,利用hash结构进行存储,从而每次处理时仅获取一部分数据
十、总结
大key和大value的危害是一致的:内存不均、阻塞请求、阻塞网络。
key由于比value需要做更多的操作如hashcode、链表中比较等操作,所以会比value更多一些内存相关开销。
本文主要详细介绍了大Key产生的原因、影响、检测方法和解决方案。通过优化数据结构设计、设定合理的数据过期策略、优化系统架构和配置,以及渐进式删除大Key等方法,我们可以有效地解决和预防大Key问题,从而提高Redis系统的稳定性和性能。
到此这篇关于redis大key和大value的危害及解决的文章就介绍到这了,更多相关redis大key和大value内容请搜索电脑手机教程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持电脑手机教程网!