MongoDB数据库性能监控详解
目录
- 一、MongoDB启动超慢
- 1、启动日常卡住,根本不用为了截屏而快速操作,MongoDB启动真的超级慢~~
- 2、启动MongoDB配置服务器,间歇性失败。
- 3、查看MongoDB日志,分析“MongoDB启动慢”的原因。
- 4、耗时“一小时”,MongoDB启动成功!
- 二、原因分析
- 三、监控MongoDB内存使用情况
- 四、监控MongoDB磁盘空间
- 五、MongoDB常用命令
- 1、MongoDB获取系统信息
- 2、MongoDB获取系统内存情况
- 3、MongoDB获取连接数信息
- 4、MongoDB获取全局锁信息
- 5、MongoDB获取操作统计计数器
- 6、MongoDB获取数据库状态信息
- 六、MongoDB持久性
一、MongoDB启动超慢
1、启动日常卡住,根本不用为了截屏而快速操作,MongoDB启动真的超级慢~~


2、启动MongoDB配置服务器,间歇性失败。

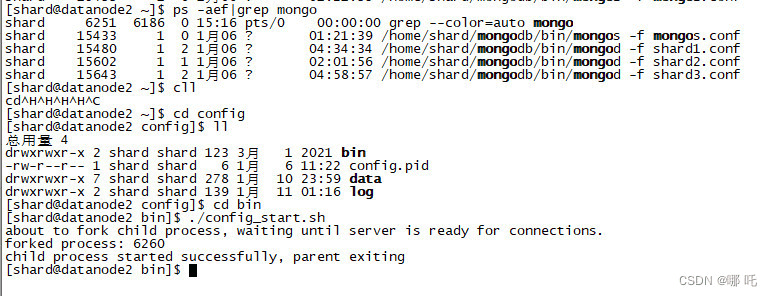
3、查看MongoDB日志,分析“MongoDB启动慢”的原因。

4、耗时“一小时”,MongoDB启动成功!

二、原因分析
在MongoDB关闭之前,有较大的索引建立的操作没有完成,MongoDB就直接shutdown了,等MongoDB再次启动的时候,MongoDB默认会将这个index重建好,重建期间处于startup状态。
由于不清楚重建索引需要多久,因此可以通过重启mongod时加上–noIndexBuildRetry参数来跳过索引重建。等启动完成后,再创建这个索引。
下面从几方面,监控一下MongoDB的性能问题。
三、监控MongoDB内存使用情况
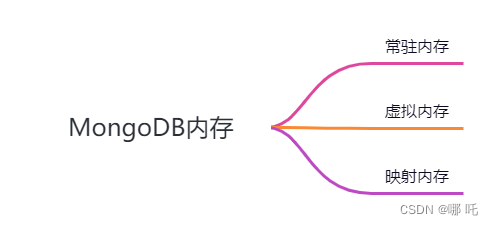
- 常驻内存: 是MongoDB在RAM中显式拥有的内存。如果查询一个集合数据,MongoDB会将其放入常驻内存中,MongoDB会获得其地址,这个地址不是RAM中数据的真实地址,而是一个虚拟地址。MongoDB可以将它传递给内核,内核会查找出数据的真实位置。如果内核需要从内存中清理缓存,MongoDB仍然可以通过该地址对其进行访问。MongoDB会向内核请求内存,然后内核会查看数据缓存,如果发现数据不存在,就会产生缺页错误并将数据复制到内存中,最后再返给MongoDB。
- MongoDB的虚拟内存: 是操作系统提供的一种抽象,它对软件进程隐藏了物理存储的细节。每个进程都可以看到一个连续的内存地址空间。在Ops Manager中,MongoDB的虚拟内存是映射内存的两倍。
- MongoDB的映射内存: 包含MongoDB曾经访问过的所有数据。

四、监控MongoDB磁盘空间
当磁盘空间不足时,可以进行如下操作:
可以添加一个分片;
删除未使用的索引;
可以执行压缩操作;
关闭副本集成员,将其数据复制到更大的磁盘中挂载;
用较大驱动器的成员替换副本集中的成员;
五、MongoDB常用命令
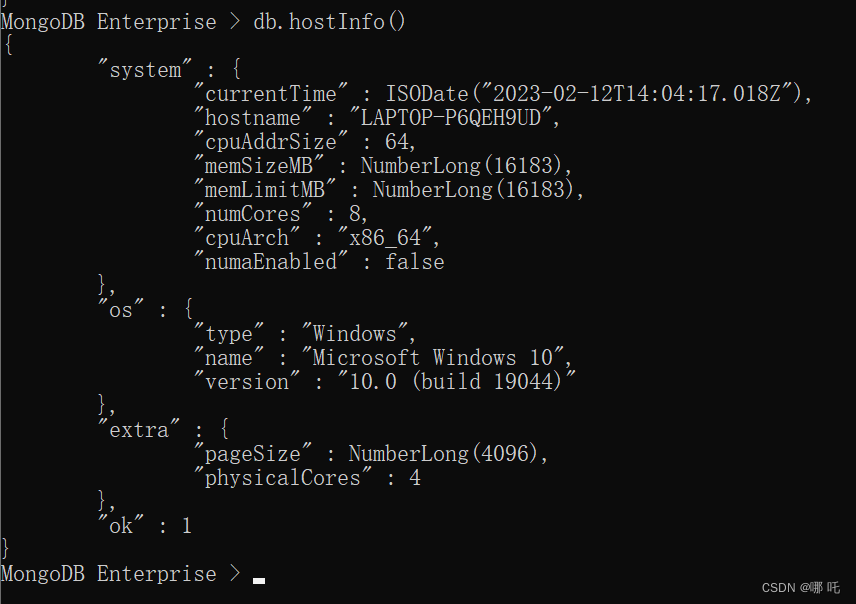
1、MongoDB获取系统信息
db.hostInfo()
2、MongoDB获取系统内存情况
db.serverStatus().mem

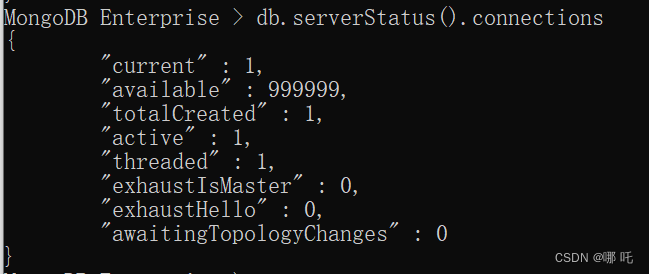
3、MongoDB获取连接数信息
db.serverStatus().connections
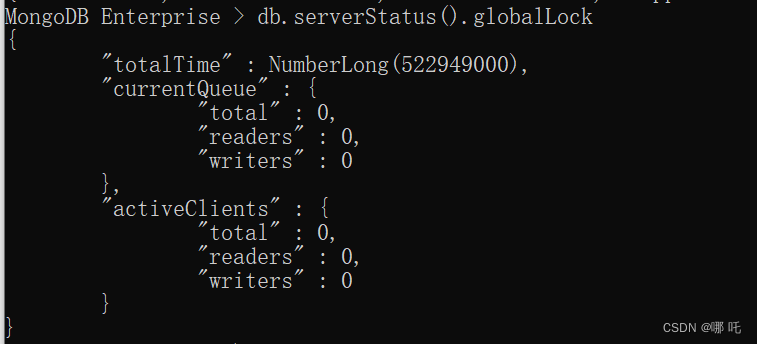
4、MongoDB获取全局锁信息
db.serverStatus().globalLock
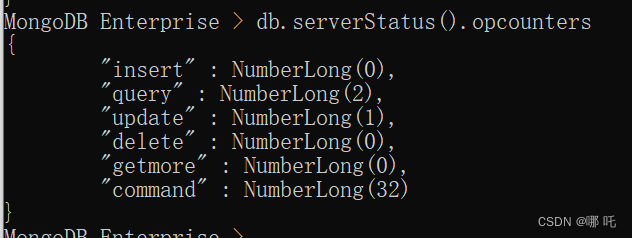
5、MongoDB获取操作统计计数器
db.serverStatus().opcounters
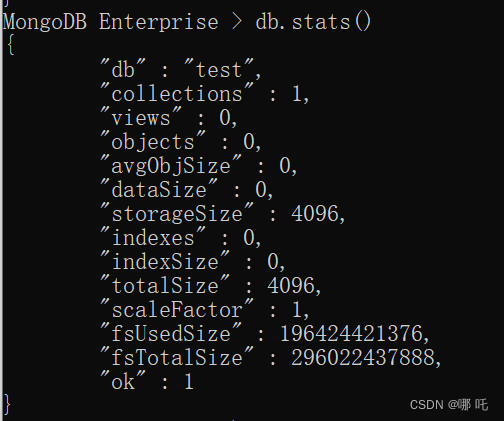
6、MongoDB获取数据库状态信息
db.stats()
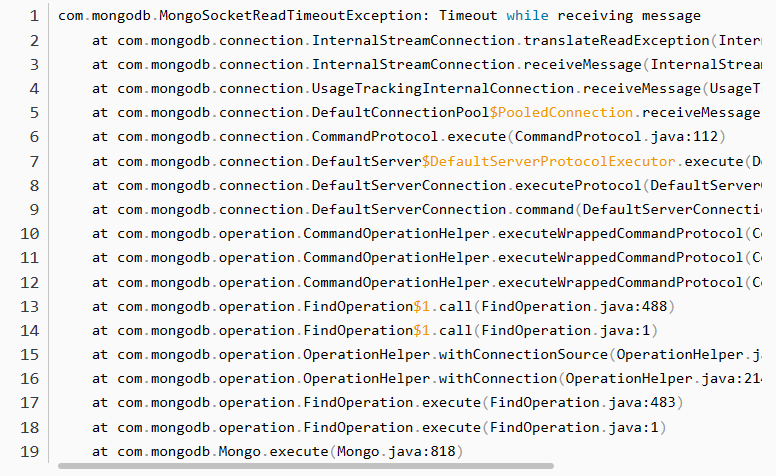
以上是MongoDB的重要指标,通过这些指标我们可以了解到MongoDB的运行状态,评估数据库的健康程度,并快速确定实际项目中遇到的性能瓶颈。
比如项目中遇到的MongoSocketReadTimeoutException:

六、MongoDB持久性
复制延迟是指从节点无法跟上主节点的速度。
从节点一个操作的时间减去主节点此操作的时间,就是复制延迟。延迟应该尽可能的接近0,并且通常是毫秒级的。
备份操作通常会将所有数据读入内存,因此,备份操作通常应该在副本集从节点而不是主节点进行,如果是单机MongoDB,则应该在空间时间进行备份,比如深夜凌晨。
持久性是数据库必备的一种特性,想象一下,如果数据库不具备持久性,如果数据库重启,数据全部丢失,太可怕了,不敢想。
为了在服务器发生故障时提供持久性,MongoDB使用预写式日志机制,英文简称 WAL。WAL是数据库系统中一种常见的持久性技术。在数据存入数据库之前,将这些更改操作写到磁盘上。
从MongoDB4.0开始,执行写操作时,MongoDB会使用与oplog相同的格式创建日志。oplog语句具有幂等性,不管执行多少次,结果都是一样的。
MongoDB还维护了日志和数据库数据文件的内存视图。默认情况,每50毫秒会将日志条目刷新到磁盘上,每60秒会将数据库文件刷新到磁盘上。刷新数据的时间60秒间隔被称为检查点。日志用于将上一个检查点之后的数据提供持久性。MongoDB的持久性就是在发生故障时,重启之后,将日志中的语句重新执行一遍,以保证在关闭前丢失的数据重新刷新到MongoDB中。
MongoDB会在data目录下创建一个journal的子目录,WiredTiger日志文件的名称为WiredTigerLog.<sequence>。sequence是一个从0 000 000 001开始的数字。
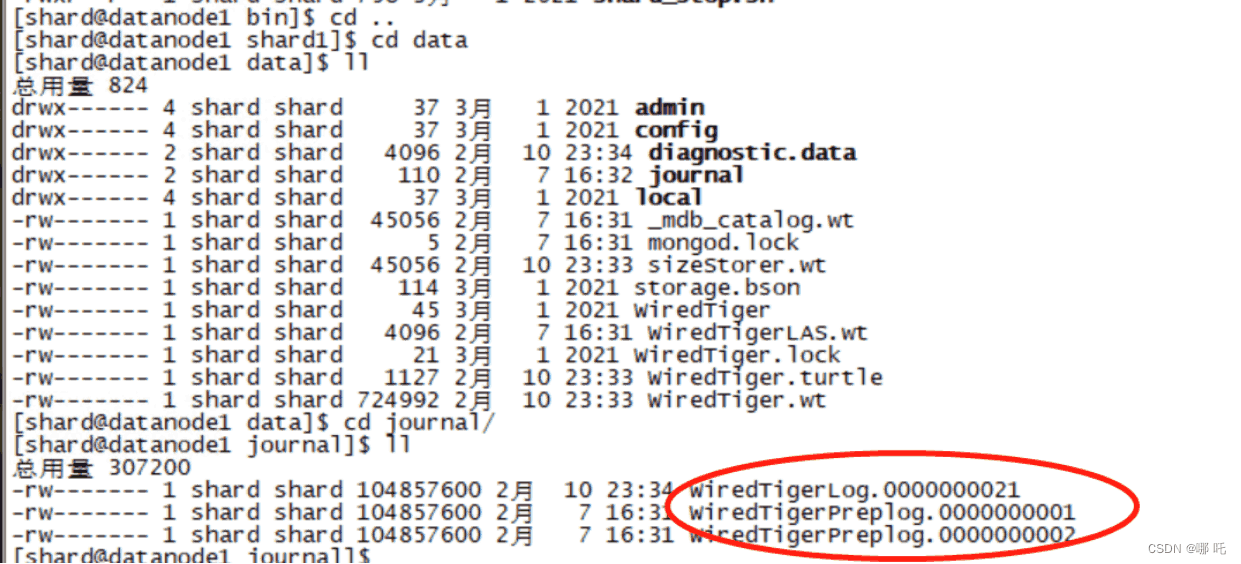
MongoDB会对写入的日志进行压缩,日志文件限制的最大大小为100MB。如果大于100MB,MongoDB就会自动创建一个新的日志文件,由于日志文件只需在上次检查点之后恢复数据,因此在新的检查点写入完成时,旧的日志文件就会被删除。


