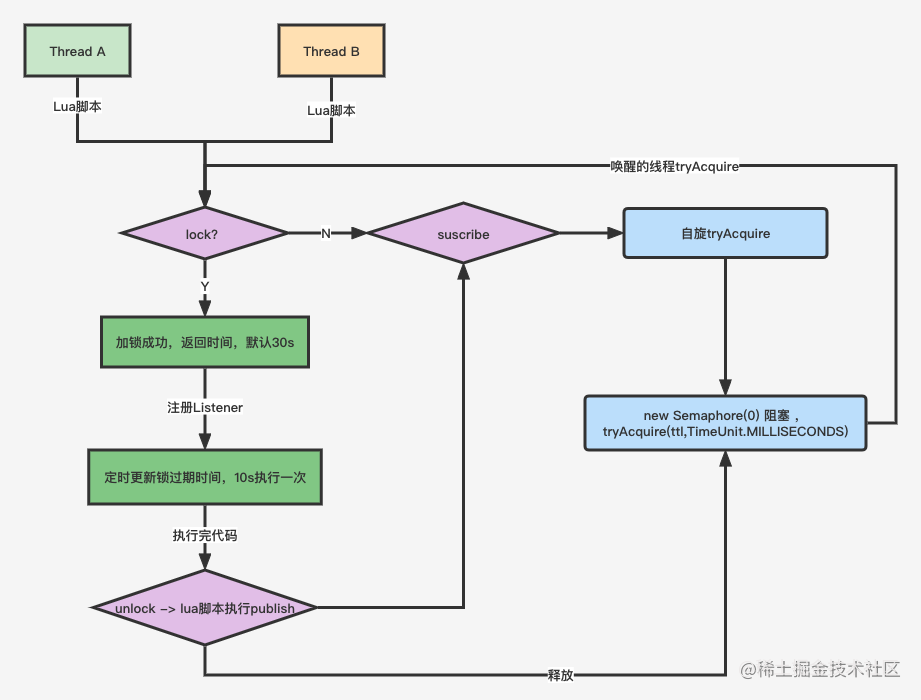
Redis使用布隆过滤器解决缓存雪崩的问题
目录
- 背景介绍
- 概念说明
- 原理说明
- 解决穿透
- 安装使用
- 安装过程
- Redis为普通安装的配置方式
- Redis为Docker镜像安装的配置方式
- 具体使用
- 控制台操作命令说明
- Spring Boot集成布隆过滤器
- 总结提升
背景介绍
布隆过滤器可以帮助我们解决Redis缓存雪崩的问题,那什么是布隆过滤器、布隆过滤器又是如何使用如何解决缓存雪崩的问题的,让我们带着这一系列的问题去详细了解布隆过滤器。
概念说明
布隆过滤器是一种用于快速判断一个元素是否属于一个集合的数据结构。它通常用于大规模数据集合中,可以快速判断一个元素是否可能存在于集合中,但不能确定一定存在。布隆过滤器的主要优点是占用内存少、查询速度快,并且可以容忍一定的误判率。
原理说明
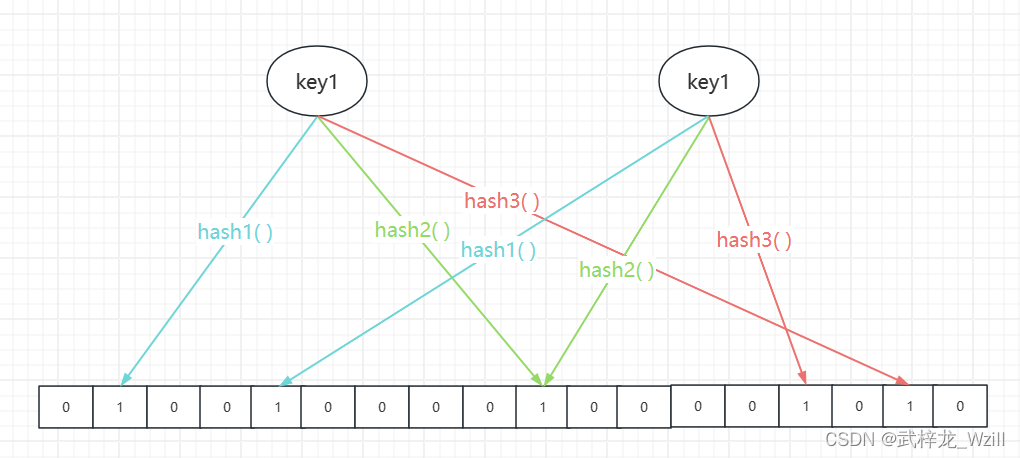
布隆过滤器由一个位数组和多个哈希函数组成。位数组通常初始化为0,哈希函数用于将元素映射到位数组中的多个位置。当一个元素被加入到布隆过滤器中时,它会被哈希函数映射到位数组的多个位置,然后将这些位置的值设为1。当查询一个元素是否存在于布隆过滤器中时,哈希函数会将元素映射到位数组的多个位置,然后检查这些位置的值是否都为1,如果有一个位置的值为0,则可以确定元素一定不存在于集合中,如果所有位置的值都为1,则元素可能存在于集合中。
布隆过滤器的误判率取决于位数组的大小和哈希函数的数量。通常情况下,误判率随着位数组大小的增加而减小,但会占用更多的内存。因此,使用布隆过滤器时需要根据实际情况权衡误判率和内存占用。
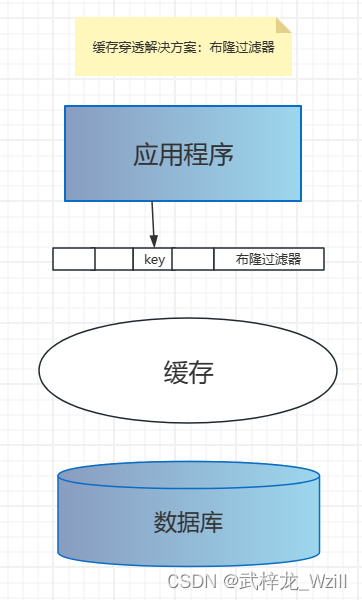
解决穿透
我们还可以在存储和缓存之前,加?个布隆过滤器,做?层过滤。布隆过滤器?会保存数据是否存在,如果判断数据不存在,就不会访问存储。
安装使用
安装过程
Redis为普通安装的配置方式
1、下载布隆过滤器这个插件
wget https://github.com/RedisLabsModules/rebloom/archive/v2.2.6.tar.gz
2、解压文件
tar -zxvf v2.2.6.tar.gz

3、编辑插件
# 到RedisBloom对应目录 cd /usr/local/redis/RedisBloom-2.2.6 # 编译插件 make
4、Redis集成RedisBloom插件
# vim查看redis.conf vim /usr/local/redis/config/redis.conf # 在文件后面添加如下配置 loadmodule /usr/local/redis/RedisBloom-2.2.6/redisbloom.so
5、配置完之后重启Redis即可。
Redis为Docker镜像安装的配置方式
1、创建文件夹以及配置文件,用于挂在redis启动的后容器中的文件,方便我们在容器外部操作redis的配置
mkdir data ##创建文件夹 touch redis.conf ## 创建文件
2、在我们创建的redis.conf文件中添加一行配置loadmodule /data/RedisBloom-2.2.6/redisbloom.so

3、随后直接使用dokcer run命令进行启动
docker run -p 6379:6379 --name redis -v /root/redis/data:/data -v /root/redis/redis.conf:/etc/redis/redis.conf --restart=always --network host -d redis:5.0.7 redis-server /etc/redis/redis.conf
这个命令是用于在 Docker 中运行 Redis 容器,并进行一些配置。下面是对每个参数的解释:
- -p 6379:6379: 将 Docker 容器的端口 6379 映射到主机的端口 6379,以便可以从主机访问 Redis 服务。
- –name redis: 指定容器的名称为 “redis”。
- -v /root/redis/data:/data: 将主机的 /root/redis/data 目录挂载到容器的 /data 目录,用于持久化保存 Redis 数据。
- -v /root/redis/redis.conf:/etc/redis/redis.conf: 将主机的 /root/redis/redis.conf 配置文件挂载到容器的 /etc/redis/redis.conf,使用该配置文件作为 Redis 的配置。
- –restart=always: 设置容器在退出时自动重新启动。
- –network host: 使用主机网络模式,容器将共享主机的网络栈。
- -d: 在后台运行容器。
- redis:5.0.7: 指定使用的 Redis 镜像及其版本号。
- redis-server /etc/redis/redis.conf: 在容器中执行的命令,即启动 Redis 服务器,并使用指定的配置文件。
执行上述操作redis容器如果启动没有问题那么我们的布隆过滤器的插件和redis都安装并启动成功了,如果没有启动成功可以通过docker logs 查看一下redis的启动过程中出现什么问题。
具体使用
控制台操作命令说明
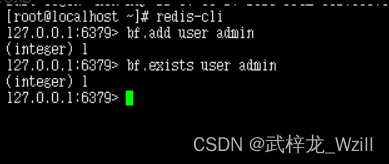
- BF.ADD:向布隆过滤器中添加一个元素。
BF.ADD <key> <item>
- BF.EXISTS:检查一个元素是否存在于布隆过滤器中。
BF.EXISTS <key> <item>
- -BF.MADD:向布隆过滤器中批量添加多个元素。
BF.MADD <key> <item> [item ...]
- BF.MEXISTS:批量检查多个元素是否存在于布隆过滤器中。
BF.MEXISTS <key> <item> [item ...]
- BF.INFO:获取布隆过滤器的信息,包括容量、误判率等。
BF.INFO <key>
- BF.RESERVE:创建一个新的布隆过滤器,并指定容量和误判率。
BF.RESERVE <key> <error_rate> <capacity>
- BF.COUNT:统计布隆过滤器中已添加的元素数量。
BF.COUNT <key>
给user过滤器添加一个元素,如果我们没有添加创建布隆过滤器,系统会给我们创建一个,其中布隆过滤器的容量为100,判错率为0.01这是布隆过滤器的默认配置,我们可以在创建布隆过滤器的时候进行修改。
Spring Boot集成布隆过滤器
1、引入依赖:这里使用的redis的过滤器所以用到的依赖直接使用的spring-data-redis这个就可以了。
<!--redis的依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2、布隆过滤器的工具类
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.data.redis.core.script.RedisScript;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
@Component
public class RedisBloomUtil {
@Autowired
private RedisTemplate redisTemplate;
// 初始化一个布隆过滤器
public Boolean tryInitBloomFilter(String key, long expectedInsertions, double falseProbability) {
Boolean keyExist = redisTemplate.hasKey(key);
if(keyExist) {
return false;
}
RedisScript<Boolean> script = new DefaultRedisScript<>(bloomInitLua(), Boolean.class);
RedisSerializer stringSerializer = redisTemplate.getStringSerializer();
redisTemplate.execute(script, stringSerializer, stringSerializer, Collections.singletonList(key), falseProbability+"", expectedInsertions+"");
return true;
}
// 添加元素
public Boolean addInBloomFilter(String key, Object arg) {
RedisScript<Boolean> script = new DefaultRedisScript<>(addInBloomLua(), Boolean.class);
return (Boolean) redisTemplate.execute(script, Collections.singletonList(key), arg);
}
@Transactional
// 批量添加元素
public Boolean batchAddInBloomFilter(String key, Object... args) {
RedisScript<Boolean> script = new DefaultRedisScript<>(batchAddInBloomLua(), Boolean.class);
return (Boolean) redisTemplate.execute(script, Collections.singletonList(key), args);
}
// 查看某个元素是否是存在
public Boolean existInBloomFilter(String key, Object arg) {
RedisScript<Boolean> script = new DefaultRedisScript<>(existInBloomLua(), Boolean.class);
return (Boolean) redisTemplate.execute(script, Collections.singletonList(key), arg);
}
// 批量查看元素是否存在
public List batchExistInBloomFilter(String key, Object... args) {
RedisScript<List> script = new DefaultRedisScript(batchExistInBloomLua(), List.class);
List<Long> results = (List) redisTemplate.execute(script, Collections.singletonList(key), args);
List<Boolean> booleanList = results.stream().map(res -> res == 1 ? true : false).collect(Collectors.toList());
return booleanList;
}
private String bloomInitLua() {
return "redis.call('bf.reserve', KEYS[1], ARGV[1], ARGV[2])";
}
private String addInBloomLua() {
return "return redis.call('bf.add', KEYS[1], ARGV[1])";
}
private String batchAddInBloomLua() {
StringBuilder sb = new StringBuilder();
sb.append("for index, arg in pairs(ARGV)").append("\r\n");
sb.append("do").append("\r\n");
sb.append("redis.call('bf.add', KEYS[1], arg)").append("\r\n");
sb.append("end").append("\r\n");
sb.append("return true");
return sb.toString();
}
private String existInBloomLua() {
return "return redis.call('bf.exists', KEYS[1], ARGV[1])";
}
private String batchExistInBloomLua() {
StringBuilder sb = new StringBuilder();
sb.append("local results = {}").append("\r\n");
sb.append("for index, arg in pairs(ARGV)").append("\r\n");
sb.append("do").append("\r\n");
sb.append("local exist = redis.call('bf.exists', KEYS[1], arg)").append("\r\n");
sb.append("table.insert(results, exist)").append("\r\n");
sb.append("end").append("\r\n");
sb.append("return results;");
return sb.toString();
}
}
总结提升
布隆过滤器适用于需要快速判断一个元素是否可能存在于集合中的场景,例如网络爬虫中的去重、缓存中的数据判断等。但需要注意的是,布隆过滤器无法删除元素,也无法准确地判断一个元素是否存在于集合中,因此在一些场景下可能会产生误判。