时序数据库VictoriaMetrics源码解析之写入与索引
目录
- 一. 存储格式
- 二. 整体流程
- 三. 写入代码
- 1.入口代码
- 2.写入流程的代码
- 3.写index
- 4. 生成TSID
- 5. 创建index items
- 6. index items存入内存shards
一. 存储格式
下图是向VictoriaMetrics写入prometheus协议数据的示例:

VM在收到写入请求时,会对请求中包含的时序数据做转换处理:
- 首先,根据metrics+labels组成的MetricName,生成一个唯一标识TSID;
然后:
- metric(指标名称__name__) + labels + TSID作为索引index;
- TSID + timestamp + value作为数据data;
- 最后,索引index和数据data分别进行存储和检索;
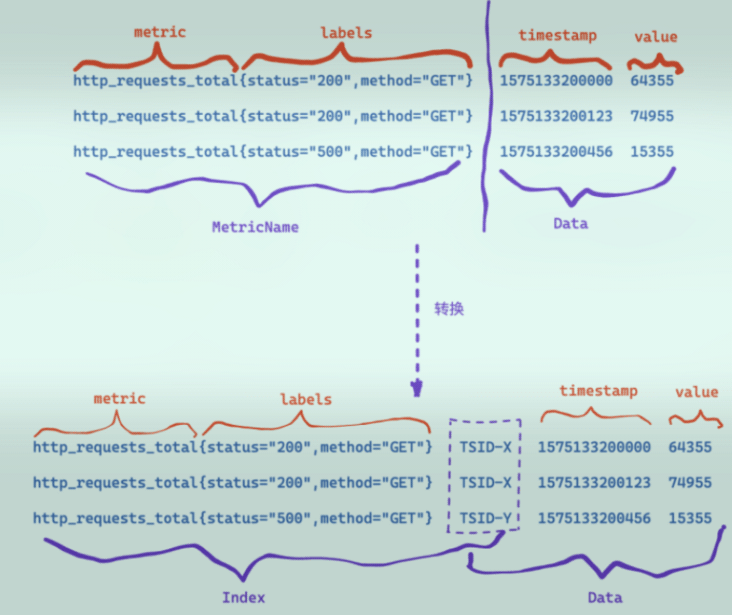
因此,VM的数据整体上分为索引和数据2个部分:
- 索引部分,用以支持按照label或tag进行多维检索,得到TSID;
- 数据部分,用以支持按照TSID得到tv数据;
二. 整体流程
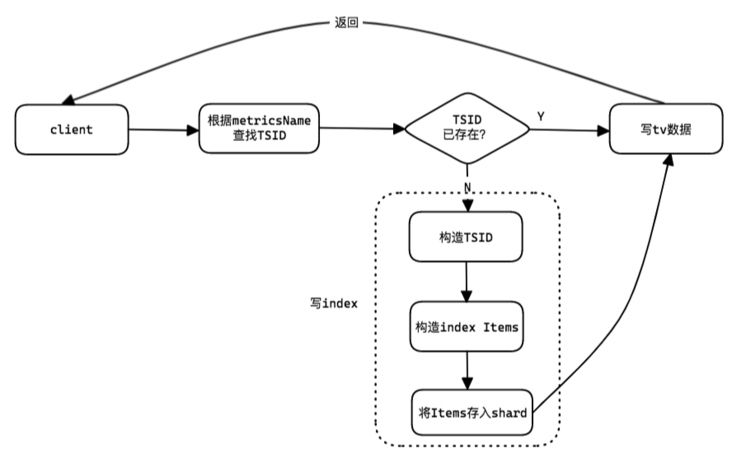
VictoriaMetrics在写入原始的rows数据时,写入过程分为两个部分:
- 写index;
- 写tv;
写入流程:
- 对于原始的rows数据,根据其metricsName从cache和内存索引中,查找其对应的TSID;
- 若TSID找到,则写入tv数据,返回client;
否则:
写index:
- 构造TSID,构造新的index items,然后将其写入内存shard;
- 内存shard被异步的goroutine压缩并保存到磁盘;
- 写tv数据;
- 返回client;
三. 写入代码
1.入口代码
vmstorage监听tcp端口,收到vminsert的插入请求后,进行处理:
// app/vmstorage/servers/vminsert.go
func (s *VMInsertServer) run() {
...
for {
c, err := s.ln.Accept()
...
go func() {
bc, err := handshake.VMInsertServer(c, compressionLevel)
...
err = clusternative.ParseStream(bc, func(rows []storage.MetricRow) error {
vminsertMetricsRead.Add(len(rows))
return s.storage.AddRows(rows, uint8(*precisionBits)) // 入口代码
}, s.storage.IsReadOnly)
...
}()
}
}写入时,1次最多写8K个rows:
func (s *Storage) AddRows(mrs []MetricRow, precisionBits uint8) error {
....
maxBlockLen := len(ic.rrs)
for len(mrs) > 0 {
mrsBlock := mrs
// 一次最多写8K,maxBlockLen=8000
if len(mrs) > maxBlockLen {
mrsBlock = mrs[:maxBlockLen]
mrs = mrs[maxBlockLen:]
} else {
mrs = nil
}
// 写入8K rows的数据
if err := s.add(ic.rrs, ic.tmpMrs, mrsBlock, precisionBits); err != nil {
if firstErr == nil {
firstErr = err
}
continue
}
atomic.AddUint64(&rowsAddedTotal, uint64(len(mrsBlock)))
}
....
}2.写入流程的代码
写入过程主要分2步:
首先,为row查找或构建TSID;
- 若该row的metricNameRaw与prevMetricNameRaw,则使用prevTSID;
- 若cache中有缓存的metricNameRaw,则使用缓存的metricNameRaw对应的TSID;
若上述都不满足,则去内存索引中查找,或者创建一个新的TSID;
- 这一步是最耗时的;
- 然后,构建TSID完毕后,插入tv数据;
// lib/storage/storage.go
func (s *Storage) add(rows []rawRow, dstMrs []*MetricRow, mrs []MetricRow, precisionBits uint8) error {
...
// 1.构造r.TSID
// 若跟prevMetricNameRaw相同,则使用pervTSID;
// 若cache中有metricNameRaw,则使用cache.TSID;
for i := range mrs {
mr := &mrs[i]
...
dstMrs[j] = mr
r := &rows[j]
j++
r.Timestamp = mr.Timestamp
r.Value = mr.Value
r.PrecisionBits = precisionBits
if string(mr.MetricNameRaw) == string(prevMetricNameRaw) { // 使用prevTSID
// Fast path - the current mr contains the same metric name as the previous mr, so it contains the same TSID.
// This path should trigger on bulk imports when many rows contain the same MetricNameRaw.
r.TSID = prevTSID
continue
}
if s.getTSIDFromCache(&genTSID, mr.MetricNameRaw) { // 使用缓存的TSID
...
r.TSID = genTSID.TSID
prevTSID = r.TSID
prevMetricNameRaw = mr.MetricNameRaw
...
continue
}
...
}
if pmrs != nil {
// Sort pendingMetricRows by canonical metric name in order to speed up search via `is` in the loop below.
pendingMetricRows := pmrs.pmrs
sort.Slice(pendingMetricRows, func(i, j int) bool {
return string(pendingMetricRows[i].MetricName) < string(pendingMetricRows[j].MetricName)
})
prevMetricNameRaw = nil
var slowInsertsCount uint64
for i := range pendingMetricRows {
...
r := &rows[j]
j++
r.Timestamp = mr.Timestamp
r.Value = mr.Value
r.PrecisionBits = precisionBits
// 尝试去index找查找,或者创建
if err := is.GetOrCreateTSIDByName(&r.TSID, pmr.MetricName, mr.MetricNameRaw, date); err != nil {
...
continue
}
genTSID.generation = idb.generation
genTSID.TSID = r.TSID
// 放回cache
s.putTSIDToCache(&genTSID, mr.MetricNameRaw)
prevTSID = r.TSID
prevMetricNameRaw = mr.MetricNameRaw
}
}
...
dstMrs = dstMrs[:j]
rows = rows[:j]
err := s.updatePerDateData(rows, dstMrs)
if err != nil {
err = fmt.Errorf("cannot update per-date data: %w", err)
} else {
// TSID构造完毕,开始插入数据
err = s.tb.AddRows(rows)
...
}
...
return nil
}3.写index
写index是slow path,重点看一下:
- 首先,去内存索引中找TSID,若找到,则返回;
- 否则,创建一个新的TSID;
// lib/storage/index_db.go
func (is *indexSearch) GetOrCreateTSIDByName(dst *TSID, metricName, metricNameRaw []byte, date uint64) error {
// 1.首先尝试在index中查找
if is.tsidByNameMisses < 100 {
err := is.getTSIDByMetricName(dst, metricName)
// 在index中找到了
if err == nil {
// Fast path - the TSID for the given metricName has been found in the index.
is.tsidByNameMisses = 0
if err = is.db.s.registerSeriesCardinality(dst.MetricID, metricNameRaw); err != nil {
return err
}
return nil
}
is.tsidByNameMisses++
} else {
is.tsidByNameSkips++
if is.tsidByNameSkips > 10000 {
is.tsidByNameSkips = 0
is.tsidByNameMisses = 0
}
}
// 2.没有找到,那么创建一个
if err := is.createTSIDByName(dst, metricName, metricNameRaw, date); err != nil {
userReadableMetricName := getUserReadableMetricName(metricNameRaw)
return fmt.Errorf("cannot create TSID by MetricName %s: %w", userReadableMetricName, err)
}
return nil
}4. 生成TSID
具体生成TSID的逻辑:
- MetricGroupID: 由metricGroup hash而来;
- JobID:由tags[0].Value hash而来;
- InstanceID:由tags[1].Value hash而来;
// lib/storage/index_db.go
func generateTSID(dst *TSID, mn *MetricName) {
dst.AccountID = mn.AccountID
dst.ProjectID = mn.ProjectID
dst.MetricGroupID = xxhash.Sum64(mn.MetricGroup)
if len(mn.Tags) > 0 {
dst.JobID = uint32(xxhash.Sum64(mn.Tags[0].Value))
}
if len(mn.Tags) > 1 {
dst.InstanceID = uint32(xxhash.Sum64(mn.Tags[1].Value))
}
dst.MetricID = generateUniqueMetricID()
}而TSID中的metricID是由启动时的时间戳+1产生:
// Returns local unique MetricID.
func generateUniqueMetricID() uint64 {
return atomic.AddUint64(&nextUniqueMetricID, 1)
}
var nextUniqueMetricID = uint64(time.Now().UnixNano())5. 创建index items
- 创建 MetricName -> TSID index;
- 创建 MetricID -> MetricName index;
- 创建 MetricID -> TSID index;
- 创建 tag -> MetricID 和 MetricGroup+tag -> MetricID index;
- 最后,将index items存入内存shards;
// lib/storage/index_db.go
func (is *indexSearch) createGlobalIndexes(tsid *TSID, mn *MetricName) {
// The order of index items is important.
// It guarantees index consistency.
ii := getIndexItems()
defer putIndexItems(ii)
// Create MetricName -> TSID index.
ii.B = append(ii.B, nsPrefixMetricNameToTSID)
ii.B = mn.Marshal(ii.B)
ii.B = append(ii.B, kvSeparatorChar)
ii.B = tsid.Marshal(ii.B)
ii.Next()
// Create MetricID -> MetricName index.
ii.B = marshalCommonPrefix(ii.B, nsPrefixMetricIDToMetricName, mn.AccountID, mn.ProjectID)
ii.B = encoding.MarshalUint64(ii.B, tsid.MetricID)
ii.B = mn.Marshal(ii.B)
ii.Next()
// Create MetricID -> TSID index.
ii.B = marshalCommonPrefix(ii.B, nsPrefixMetricIDToTSID, mn.AccountID, mn.ProjectID)
ii.B = encoding.MarshalUint64(ii.B, tsid.MetricID)
ii.B = tsid.Marshal(ii.B)
ii.Next()
prefix := kbPool.Get()
prefix.B = marshalCommonPrefix(prefix.B[:0], nsPrefixTagToMetricIDs, mn.AccountID, mn.ProjectID)
ii.registerTagIndexes(prefix.B, mn, tsid.MetricID)
kbPool.Put(prefix)
is.db.tb.AddItems(ii.Items) // 将items存入内存shards
}6. index items存入内存shards
Index items构造完成后,被写入内存的shards,会有异步的goroutine将其压缩写入disk。
写内存shards的方法: roundRobin
- 内存中有若干个index shards;
- 写入时,轮转写入:idx++ % shards
// lib/mergeset/table.go
func (riss *rawItemsShards) addItems(tb *Table, items [][]byte) {
shards := riss.shards
shardsLen := uint32(len(shards))
for len(items) > 0 {
n := atomic.AddUint32(&riss.shardIdx, 1)
idx := n % shardsLen
items = shards[idx].addItems(tb, items)
}
}内存中shards总数,跟cpu核数有关系:
- shards总数 = (cpu*cpu + 1) / 2
- 对于4C的机器,有8个shards;
// lib/mergeset/table.go
/ The number of shards for rawItems per table.
//
// Higher number of shards reduces CPU contention and increases the max bandwidth on multi-core systems.
var rawItemsShardsPerTable = func() int {
cpus := cgroup.AvailableCPUs()
multiplier := cpus
if multiplier > 16 {
multiplier = 16
}
return (cpus*multiplier + 1) / 2
}()

