?PostgreSQL?与MongoDB使用对比分析
目录
- PostgreSQL 对 JSON 的支持
- PostgreSQL 和 MongoDB 使用对比
- 1. CRUD
- 2. 索引
- 3. sharding
- 总结
在进行技术选型时,需要考虑众多因素,如功能、性能、可靠性、成本效益、社区支持和团队技术能力等,然而,影响最终决定的关键因素的往往是团队 Leader 的技术品味,这也能解释为什么阿里偏爱 Java,而字节跳动更倾向 Go、Rust 等新兴语言。技术本身无好坏之分,根据实际业务问题选择适当的技术方案是关键。
本文旨在为读者提供一种新的选择,而非论证 PostgreSQL 比 MongoDB 更优秀。
MongoDB 因其灵活的 "Schema-less"(无模式)特性而著名。"Schema-less" 意味着 MongoDB 不要求严格定义数据的结构和字段(使用 BSON 格式存储数据),允许在同一集合中存储具有不同结构的文档,这为开发人员提供了极大的灵活性,能够轻松适应数据模型的变化和演进。
PostgreSQL 提供的 JSONB 类型可用于存储和处理 JSON 数据,包括嵌套的对象、数组和基本数据类型。因此,PostgreSQL 具备 MongoDB 存储 document 的能力。
PostgreSQL 对 JSON 的支持
我们来了解一下 PostgreSQL 支持 JSON 特性的时间线(统计到版本 14):
- PG 9.2 Introduction of JSON (JSON text; no indexes) -- 2012/9/10
- PG 9.4 Introduction of JSONB (binary format; indexes) -- 2014/12/18
- PG 9.5 jsonb_set(), jsonb_object(), jsonb_build_object(), jsonb_build_array, jsonb_agg, || operator etc.
- PG 9.6 jsonb_insert()
- PG 10 Full text search support for JSONB
- PG 11 jsonb_plpython
- PG 12 json_path (like xpath in XML; part of SQL Standard 2016)
- PG 13 jsonpath.datetime()
- PG 14 JSONB subscripting can be used to extract and assign to portions of JSONB
可以看出,PostgreSQL 对 JSON 的支持虽晚于 MongoDB(MongoDB 1.0 在 2009年9月前后发布),但其后续的版本 JSON 相关的特性开发非常活跃,提供了强大而灵活的 JSON 处理能力。
PostgreSQL提供两种存储 JSON[1] 的数据类型:
json 和 jsonb,二者接受几乎相同的输入值,主要区别在存取效率。json 存储插入文本的精确副本,处理函数在每次执行时必须重新解析;jsonb 则存储解析过的的二进制格式(类似 MongoDB 的 BSON),由于需要额外的转换开销,插入时稍慢一些,但因为无需重新解析,处理速度更胜一筹。另外 jsonb 还支持索引,这是一个重要的优势。大多数场景我们都应该使用
jsonb,除非以下几种情况:• 需要保留原始输入的格式,比如空格
• 需要保留键的顺序或冗余的键值
• 需要快速插入和读取而无需对数据进行处理
PostgreSQL 和 MongoDB 使用对比
在了解了 PostgreSQL 的 JSON 特性之后,我们来对比一下 PostgreSQL 和 MongoDB 使用上的区别。
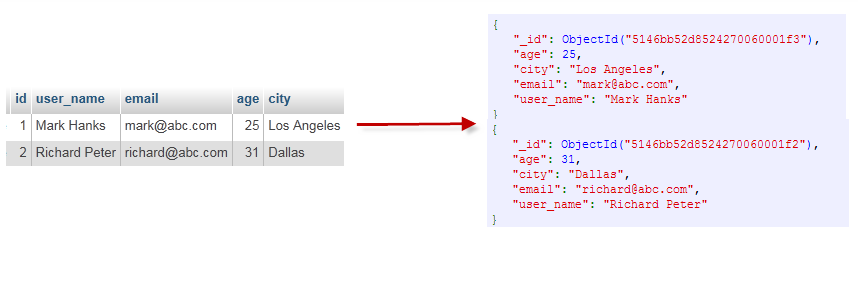
我们将 MongoDB 的
_id 单独存为一个字段,其它字段存为 doc:create table inventory(_id bigserial PRIMARY KEY , doc jsonb);
1. CRUD
MongoDB:
db.inventory.insertOne(
{ item: "canvas", qty: 100, tags: ["cotton"], size: { h: 28, w: 35.5, uom: "cm" } }
)
db.inventory.insertMany([
{ item: "journal", qty: 25, tags: ["blank", "red"], size: { h: 14, w: 21, uom: "cm" } },
{ item: "mat", qty: 85, tags: ["gray"], size: { h: 27.9, w: 35.5, uom: "cm" } },
{ item: "mousepad", qty: 25, tags: ["gel", "blue"], size: { h: 19, w: 22.85, uom: "cm" } }
])
db.inventory.find( { tags: ["red", "blank"] } )
db.inventory.find( { qty: { $gt: 25 } } )
db.inventory.find( { "tags": { $size: 2 } } )
db.inventory.find( { 'size.h': { $lte: 20 } } )
db.inventory.updateOne( { _id: 3 }, [ { $set: { "item": "notepad"} } ] )
db.inventory.deleteOne( { qty: { $gt: 90 } } )PG:
insert into inventory(doc) values('{ "item": "canvas", "qty": 100, "tags": ["cotton"], "size": { "h": 28, "w": 35.5, "uom": "cm" } }');
insert into inventory(doc) values('{ "item": "journal", "qty": 25, "tags": ["blank", "red"], "size": { "h": 14, "w": 21, "uom": "cm" } }'),
('{ "item": "mat", "qty": 85, "tags": ["gray"], "size": { "h": 27.9, "w": 35.5, "uom": "cm" } }'),
('{ "item": "mousepad", "qty": 25, "tags": ["gel", "blue"], "size": { "h": 19, "w": 22.85, "uom": "cm" } }');
SELECT * FROM inventory WHERE doc->'tags' @> '["red", "blank"]'::jsonb;
SELECT * FROM inventory WHERE (doc->>'qty')::integer > 25;
SELECT * FROM inventory WHERE jsonb_array_length(doc->'tags') = 2;
SELECT * FROM inventory WHERE (doc->'size'->>'h')::float <= 20;
UPDATE inventory SET doc = jsonb_set(doc, '{item}', '"notepad"', true) WHERE _id = 3;
DELETE FROM inventory WHERE (doc->>'qty')::integer > 90 AND ctid IN (SELECT ctid FROM inventory LIMIT 1);注意: 将全部数据存储在 PostgreSQL 的一个
jsonb 字段虽然可行,但 jsonb 没有状态统计数据,将固定的列抽成一个单独的列往往能获得更好的查询性能。2. 索引
MongoDB 支持的索引在 PostgreSQL 中基本都支持,虽然通配符索引在 PostgreSQL 没看到类似的能力,但 PostgreSQL 的索引能力应该不逊于 MongoDB。
| MongoDB | PostgreSQL |
| Single Field indexes | B-tree Index |
| Compound Indexes | Multicolumn Indexes |
| Text Indexes | GIN Indexes + tsvector |
| Wildcard Indexes | ? |
| Geospatial Indexes | Postgis geometry GiST Indexes |
| Hashed Indexes | Hash Indexes |
| ? | BRIN Indexes |
Can PostgreSQL with its JSONB column type replace MongoDB?[2] ???? 这篇文章对 MongoDB 和 PostgreSQL 中的部分索引进行了性能对比。
3. sharding
MongoDB 使用 sharding(分片)来支持超大数据集和高吞吐量的集群部署,通过将数据集水平拆分为多个分片,并将每个分片分布在不同的服务器上。每个服务器(或分片)都可以独立处理一部分数据写入和查询负载,从而提高整个系统的扩展性和性能。其架构如下:
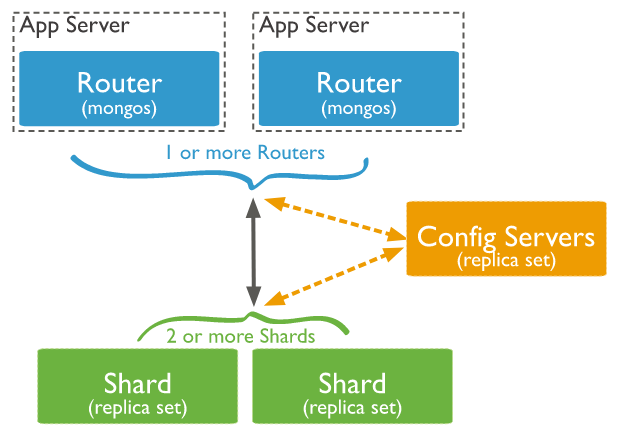
• shard: 每个 shard 可以部署为一个副本集(replica set),单个 shard 上包含多个分片
• mongos: 接收客户端的请求,并将请求路由到 shard
• config servers: 存储集群元数据和配置信息
MongoDB 在 collection 级别进行数据切分,使用 shard key(由文档中的一个或多个字段组成) 将 collection 切分为多个 chunks分布在集群中的各个分片上。
PostgreSQL 本身不支持分布式,但 Citus[3] 提供了 sharding 的能力,其组件几乎都能跟 MongoDB 对应上:
| MongoDB | Citus | |
| 数据存储节点 | shard | worker |
| 元数据存储节点 | config server | coordinator |
| 请求接入节点 | mongos | coordinator |
| 数据分布方法 | Hashed + Ranged | Hash |
| 分区级别 | collection level | schema level + table level |
| 分片名称 | chunk | shard |
PostgreSQL + Citus 能够实现 MongoDB 分片的能力。不过 Citus 不支持使用多字段作为 shard key,且只支持 Hash 分布(代码仓库中有
RANGE_DISTRIBUTED,但实际并不支持)。FerretDB
说到替换 MongoDB,不得不提一下 FerretDB[4],FerretDB 的目标是允许使用现有的关系型数据库来处理 MongoDB 的查询请求,它充当一个代理,接收来自应用程序的 MongoDB 查询,并将其转换为相应的 SQL 查询,然后将结果返回给应用程序。FerretDB 支持使用 PostgreSQL 或 SQLite 等关系型数据库作为后端存储引擎,其架构如下:

FerretDB 能够处理 MongoDB 大部分请求,但目前有些能力还不具备,如:
• $lookup aggregation pipeline[5]
• geospatial index[6]
• text indexes[7]
• sharding[8]
• ...
不过 FerretDB 的社区非常活跃,相信未来他们会将这些特性逐渐完善。
总结
相比 MongoDB 的 "Schema-less",PostgreSQL 确实需要事先定义好表结构,包括列名、数据类型和约束等,但 PostgreSQL 的 JSONB 类型提供了一种在关系型数据库中存储和查询 JSON 数据的灵活性。也正是这种表结构和 JSONB 类型相结合的能力,使得笔者认为 PostgreSQL 比 MongoDB 单纯的 "Schema-less" 更灵活、更强大。
虽然 Michael Stonebraker 早在 2005 年就指出 One size fits all[9] 是一个不切实际的观点,但数据库开发者从未停止探索的脚步,期望为用户提供一站式的解决方案。MongoDB 从最初的 NoSQL[10] 到后来支持了事务[11]、时序[12]等特性,PostgreSQL 生态也有时序(TimescaleDB[13])、图(AGE[14])、消息队列(PGMQ[15])相关的扩展。虽然在功能特性上有所重合,但不同的是,MongoDB 作为一个商业公司,其产品在易用性上会更胜一筹,而 PostgreSQL 则需要使用者不断去探索来发掘其无限可能。
最后,Michael Stonebraker 三篇关于 NoSQL 的博客:
• "Schema Later" Considered Harmful[16]: If you have data that will require a schema at some point, you are way better off doing the work up front to avoid data debt, because the cost of schema later is a lot higher.
• Comparison of JOINS: MongoDB vs. PostgreSQL[17]
• Those Who Forget the Past Are Doomed to Repeat It[18]
到此这篇关于为什么 PostgreSQL 能代替 MongoDB?的文章就介绍到这了,更多相关PostgreSQL 能代替 MongoDB内容请搜索电脑手机教程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持电脑手机教程网!